Oh well, what do you call a system log that has no entries; a malfunctioning system, right. So what would you call a supposedly web log (blog) that has no entries for almost a year and a handful in a couple years  ?
?
Despite deeply wanting to keep writing, I hardly get a chance to do so these days. But so much for the ranting, time to get down to business now.
We@Imbibe do a lot of Drupal stuff (in-house as well as consulting). This site itself, Imbibe’s site, Imbibe’s careers site and many of our other web properties are Drupal based; so are many of our client’s properties, e.g. this, this and this etc.
The development and maintenance of all these web properties, as should be obvious, involves doing stuff locally that then gets pushed out to production as well as fetching content from production to do more stuff locally (e.g. coding a client requested change to a workflow locally and pushing to production upon approval; or fetching backups of client-entered content from production so they can be customized as requested).
In almost all cases, the production environment is a highly sensitive set of servers with regulated access. And there’s bureaucracy involved in pushing content to production or fetching from it (which I agree is justified).
For sometime now, I had been looking to automate the process of sending content back and forth from and to production for these web properties in a way that required minimal manual intervention (especially minimizing or eliminating the process of requesting access to the production servers) but enough administrative oversight. At a minimum, the desirable objectives of a deployment strategy for these properties included the following:
- No need for requesting manual Shell, Hosting Panel or FTP access for production servers either for retrieving data from them or for pushing out data to them.
- Ability for our design or development team to request database backups and/or file-system backups of content uploaded to production.
- If a client authorized our in-house administrator to fetch these backups, the admin should be able to get those from production and provide to the team.
- Else an admin or manager at the client should be able to send us these backups.
In both cases, the backups should be retrievable via a web-interface satisfying condition 1 above (no manual access required to the server).
- The changes produced by design or development team should be sent for staging and approval. Once approved, either our in-house admin or the client admin should be able to trigger automatic upload of the changes to production. The upload should only send modified files to the production (and not re-upload the entire site).
- We should be able to upgrade off-the shelf modules and/or themes deployed for a Drupal install via the same deployment process. If needed, Drupal itself should be upgradable by utilizing the same deployment process.
- The entire process should be as less painful as possible with a possibility of manual oversight and approval involved wherever needed.
I would now like to switch to providing some background on Drupal that we considered while devising a way to deployment automation (these points are true for single or multi-site installations, however there are a few optimizations that can be made further for multi-site Drupal installs):
- A Drupal installation is supported by a single database (and it was MySql for all our installations).
- Drupal maintains a very clear separation between the CMS portion of a deployment and the content portion of a deployment:
- Its easy to version control the CMS portion of the deployment by using a SCM tool. We use Git but the strategy we devised isn’t tied to a particular SCM.
- The content part could mean 2 things:
- The inputted content which would normally be in a database.
- The uploaded content which would be in public or private folders of a Drupal site.
- For the uploaded content, you don’t normally need to put it under source control (in fact, you would never want to put it under source control).
- The dev/design teams usually do not need latest uploaded content from public or private folders of a Drupal installation all the time, but might need it occasionally and should be able to request it then.
- They again might not need latest content from the live database but should be able to request it if needed.
I won’t goto the brainstorming and deliberation phase which helped produce the deployment strategy I am going to describe shortly. I would rather list the high-level points of the strategy (which seems to have started working pretty well) and helped achieve the desirable objectives outlined above. You should re-read the Drupal background provided as that’s an important aspect of the entire discussion.
Now for the strategy:
- As a rule of thumb, we always put the CMS portion of the sites we manage (for ourselves or our clients) under source control.
As mentioned, we use Git for SCM (but you can use any). A couple of sites which weren’t under source control had repos created for them for automating deployment.Please note we only added Drupal or contrib portions under source control. Uploaded content (which usually includes images or auto-generated content by Drupal like minified css/js files) weren’t put under source control. Folders containing these files (which is usually the public files folder in Drupal) was actually added to .gitignore (i.e. ignore list in source control).
- All these sites are a consulting or maintenance job. So every site gets its source control repo which are totally independent.
- We create 2 branches for each repo, master and prod.
- master is where the initial content gets checked into with the production backup with site at a stable state.
- prod branch is immediately created from master.
- All further dev and customization work would happen in master. When changes get stable and approved, the commits are merged to the prod branch.
- We decided to use JetBrains’ TeamCity server for automating pushing out changes from Git to production servers. TeamCity is more often used as a continuous integration and automated build tool which it excels at, but you would be surprised how easy it is to execute custom workflows like deployment automation with TeamCity.
PS: We used TeamCity 8.x and steps below might vary a bit if your TeamCity major version is different. - A Configuration Template was created in TeamCity that would be shared by all sites where deployment was to be automated. The template:
- Named FTP Uploads had default settings for all other options on the General Settings tab.
- Had no VCS Root attached.
- No Build Step specified.
- A VCS Trigger to trigger a build every 300 seconds after a VCS change is detected.
This step is important. Our decision was to upload changes to production server 5 minutes after they were committed to the prod branch in Git. If you would rather do this manually, you should not create any Trigger in the Configuration Template then. - On the Failure conditions tab, the checkbox to Fail Build if an error message is logged by build runner was checked. Everything else was at default.
- A total of 5 System Properties was added on the Parameters tab. These were configuration options for automated FTP uploads to production server and would be discussed in more detail below and futher in a subsequent blog post.
- All other tabs were left at their defaults.
- A new build was created in TeamCity for each site where we needed to automate deployment. The build was created using the FTP Uploads Configuration Template detailed in previous step.
The build had following properties:- A site specific name given on General Settings tab and everything else at default.
- A VCS root created in Version Control Settings tab. The critical aspect is to ensure the VCS root points to the prod branch in your VCS, not the master branch.
- A single PowerShell build step which would upload changes to files in the prod branch over FTP to the production servers.
All this step does is creating a PowerShell build runner pointing to TeamCity.FtpRunner.ps1 script which is the topic of another blog post here.
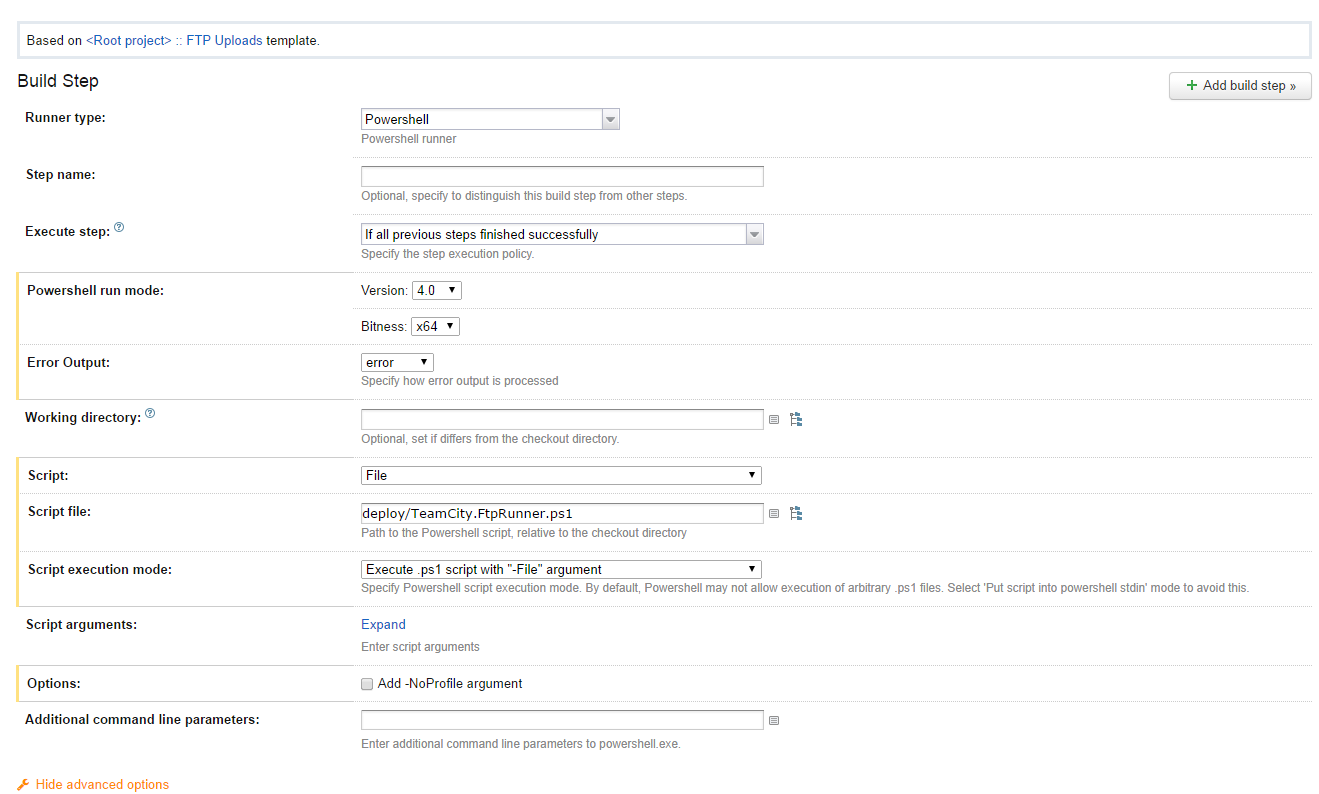
The Script option should be set to File and Script execution mode set to Execute .ps1 script with “-File” argument. Here’s a screenshot to avoid any confusion (please click to enlarge the screenshot):
- Values for FTP System Parameters defined in the Parameters tab. As mentioned already, this requires a bit more details to be explained and is covered in a separate blog post:
A PowerShell based FTP runner for TeamCity builds - All other tabs left at their defaults.
This completes what you need to push your local changes to the production server as they are committed to the prod branch in your VCS repo.
- The final part is getting database and/or uploaded content from the production site if the team needs it. This was achieved by creating a Drupal module named it_utils (Utils for Drupal from Imbibe Tech).
The module itself is open-sourced with its source on GitHub here:
https://github.com/imbibe/DrupalItUtilsThe module provides these features:
- A single-click option to download the Drupal db backup.
- A single-click option to download file-system backup of Drupal’s public files repository.
- A single-click option to download file-system backup of the entire Drupal installation itself.
Once you configure the TeamCity build for pushing out changes and the Drupal module to retrieve content from production, you have a complete 2-way workflow to push and retrieve content.
I would now again go over each point of the deployment automation objectives to illustrate how the above workflow achieves each of the objectives:
- The entire process does not need any manual access to the server in any way. FTP credentials to upload content via the TeamCity build need to be saved as the build parameters.
With TeamCity 8.1 supporting Password type build parameters which aren’t shown anywhere in TeamCity’s interface once saved, makes saving the credentials with the build configuration secure enough for regular use-cases.If you are still concerned about saving FTP credentials with the build, there are lots of other things you can do (e.g. saving the parameters in Windows Credentials vault etc and retrieving from there in your FTP upload script, but such ways are outside the scope of this blog post).
You should definitely look at the other blog post to see in more detail how build triggered FTP upload works.
- The team can request db/file-system backup.
- If the client has authorized us, we can fetch it via the it_utils Drupal module mentioned above.
- Or the client can download and send us.
In both cases, there is sufficient scope for removing sensitive information from the backups (both database or file-system) if needed before sending to our team.
- The team works in the master branch and all approved changes/enhancements are merged to prod branch. In our case, approval usually comes in-house from a manager, but if needed, you can create a separate build pointed to master branch to send changes to the client for approval before merging in prod branch.
- For upgrading contrib modules, or Drupal itself, we follow the usual process:
- Put site in maintenance mode.
- Removing existing contrib module or Drupal files from prod branch by making a commit and triggering a build.
- Add updated contrib module or Drupal files and trigger a build.
- Go through Drupal’s upgrade wizard
Mission accomplished again with no manual access to server required 🙂
- There is sufficient scope for manual oversight in each step as needed (either from in-house managers or client).
- You can look at changes in master before authorizing prod merge.
- You can auto-trigger scheduled builds for prod branch changes or login to TeamCity and trigger manually.
- You can retrieve data from prod via a web interface and clean/de-sensitive as needed before sending to our team.
All in all, everything working as needed. This has been one long textual blog post and I would add just one more aspect before wrapping it up.
The entire process is described with a Drupal-centric overtone, but you can apply it to most CMSes or web-deployments where the source code is not compiled and pushed to production in source form (i.e. it can be applied to most PHP-based projects and CMSes as well as other source-form deployed platforms).
- The build process remains the same, you just point at proper end-points.
- The only thing you need to do is to tweak the database or file-system downloads for your CMS or custom project.
If you have a look at the it_utils Drupal module, you would notice the actual logic to create backups for either the database or the file-system is written as independent functions in the inc folder inside the module. All you need to do is to call the functions via an appropriate event from your project’s or CMS’s interface. For CMS, it usually means creating a skeleton wrapper module/plugin to call those functions which should be pretty easy.
I think I would call it a day there. If you have any confusion or would like to get more details on any particular aspect or step described, feel free to ask in comments below.
FYI, the process is production tested and running successfully on this site, Imbibe’s various sites and a few of our client sites (e.g. GCM Classes).
Recent Comments